7 Файл зөөж оруулах болон гаргах

Энэ бүлэгт бид файлыг хэрхэн байрлуулах, зөөж оруулах, болон гаргах талаар тайлбарлав:
Олон төрлийн файлуудыг rio багц ашиглан
import(),export()хийж болно.Нэг компьютер дэх файлын байршил нөгөө компьютерт таарахгүй байх тохиолдлуудад here багцаар R төсөлтэй холбоотой файлуудын байршлыг тогтоох боломжтой.
-
Дараах файл импортлох жишээнүүд:
Excel–ийн тодорхой хуудаснууд (sheets)
Замбараагүй хүснэгтийн толгой, алдагдсан мөрнүүд
Google sheets
Вебсайтад тавигдсан өгөгдөл/дата
API -ууд
Хамгийн сүүлд хэрэглэж байсан файлыг оруулах
Гараар өгөгдлийг оруулах
R –т тусгай зориулагдсан файлын төрөл (RDS, RData)
Файл, графикуудыг хадгалж/экспортлох
7.1 Ерөнхий
Аливаа “dataset” –ыг R –т оруулахад шинээр data frame гэсэн обьект таны R –ын орчинд үүсч байдаг. Энэ нь таны хавтсанд хаяг/байршилтай зөөвөрлөгдсөн (e.g. Excel, CSV, TSV, RDS) файл гэж үзэгддэг.
R –т олон төрлийн дата файл оруулж болдог ба бусад статистикийн программ (SAS, STATA, SPSS) дээр үүсгэсэн файлуудыг ч оруулах боломжтой. Мөн хамааралт өгөгдлийн санд ч холбох боломжтой (relational database).
R –дээрх дата өөрийн гэсэн өргөтгөлтэй:
RDS файлд (.rds) ганц R обьектийг хадгалдаг (ж: data frame). Ялангуяа цэвэрлэгдсэн өгөгдлийг хадгалахад тохиромжтой. Учир нь цэвэрлэгдсэн өгөгдөл багана тус бүр мэдээлэл хадгалагдсан учир. Энэ талаар энэ хэсгээс тодруулж үзнэ үү.
RData файлд (.Rdata) хэд хэдэн обьект, эсвэл бүр бүтэн R-ын ажлын талбайг (workspace) хадгалахад хэрэглэж болно. Энэ талаар энэ хэсгээс тодруулж үзнэ үү.
7.2 rio багц
Бидний санал болгож буй R багц бол: rio. Энэхүү багцын нэр “R I/O” (оролт/гаралт -input/output) гэсэн үгний товчлол юм.
Энэ багцын import() болон export() функцууд нь олон төрлийн (e.g. .xlsx, .csv, .rds, .tsv) файлуудтай ажиллах чадвартай. Энэ функцуудэд файлын байршлыг (өргөтгөлтэй нь хамт ) зааж өгөхөд rio багц тухайн файлын өргөтгөлийг уншаад шаардагдах тохируулгыг хийж файлыг зөөвөрлөнө.
rio багцгүйгээр эдгээр үйлдлийг хийхэд хэд хэдэн багц хамтран оролцох шаардлагатай болдог. Багц болгон тус тус өөр өргөтгөлийг уншихад зориулагдсан байдаг. Тухайлбал read.csv() (base R), read.xlsx() (openxlsx багц), болон write_csv() (readr багц) гэх мэт функцуудыг ашиглах болдог. Эдгээрийг тэр болгон санахад бэрхшээлтэй тул rio багцын import(), export()–ыг хэрэглэх нь илүү хялбар.
rio-ын import() болон export() функцууд тухайн файлын өргөтгөлд шаардлагатай багцыг тогтоож хэрэглэдэг. rio багцын функцуудыг уншуулж байхад цаана нь ажиллаж байдаг багцуудын жагсаалттай хүснэгтийг энэ бүлгийн хамгийн ард харуулсан. Rio багцаар зөөвөрлөгддөг файлуудын дунд STATA, SAS, SPSS программын файлууд ч ордог.
Харин shapefiles–г зөөвөрлөхөд өөр багц шаардлагатай байдаг талаар [GIS үндсэн ойлголтууд] хэсэгт дэлгэрэнгүй дурдсан.
7.3 here багц
here багц болон түүний here() функц R–т таныг файлаа хаанаас олох болон хаана хадгалах талаар ойлгуулахыг хялбарчилж өгдөг. Өөрөөр хэлбэл файлын байршил үүсгэдэг.
Мөн here багц таны R төсөл дэх файлын байршлыг R төслийн үндсэн лавлахтай (хамгийн дээд түвшний хавтас) холбоотойгоор харуулдгаараа онцлог. R төслийг олон компьютер/хүмүүсийн дунд дамжуулж ажиллаж буй үед энэхүү үйлдэл их хэрэг болдог. Нэг компьютер дээрх үүсгэгдсэн файлын байршил (жишээ нь “C:/Users/Laura/Documents…”) өөр нэг компьютерт очоод таарахгүй байх асуудал нийтлэг гардаг ба here багц бүх хэрэглэгчдийг нийтлэг байршлаас (R төслийн үндсэн байршил) эхлүүлснээр үүнээс сэргийлж чаддаг.
here() нь R төслийн дотор дараах зарчмаар ажилладаг:
Анх here багцыг ачаалах үед R төслийн үндсэн хавтас дотор “.here” гэсэн жижиг файл автоматаар үүсгэгдэж “чиглүүлэх”, “холбох” үүрэг гүйцэтгэдэг.
Скрипт дотроо аливаа файлын байршлыг заах бол
here()функцыг ашиглан дээрх чиглүүлэгчтэй холбоотой файлын зам үүсгэдэг.Файлын байршлыг үүсгэхдээ оруулах хавтасны нэр (үндсэн хавтаснаас цааш)-ийг тодорхойлох цэгтэйгээр, таслалаар тусгаарлаж, файлын нэрийг өргөтгөлтэй нь хамт бичнэ. Доор жишээ харуулав.
here()файлын замыг импорт, экспортын аль алинд нь ашиглаж болно.
Жишээ нь дараах import() функц дэх файлын байршлыг here() ашиглан
оруулсан байна.
here("data", "linelists", "ebola_linelist.xlsx") гэсэн команд нь үнэн хэрэг дээрээ тухайн хэрэглэгчийн компьютерт тохирсон өвөрмөц бүтэн файлын байршлыг үүсгэж буй юм:
"C:/Users/Laura/Documents/my_R_project/data/linelists/ebola_linelist.xlsx"here() функцын гол давуу тал нь ямар ч компьютер байсан тухайн R төсөлд хүрч чаддагт байдаг.
ЗӨВЛӨГӨӨ: Хэрвээ та “.here” файлын үндэс хаана байгааг мэдэхгүй байгаа бол here() функцыг хоосон хаалттайгаар уншуулаарай.
here багцын талаарх дэлгэрэнгүй мэдээллийг энэ линкээс уншина уу.
7.4 Файлын байршил
Өгөгдлийг зөөж оруулж гаргахдаа байршлыг нь зааж өгөх хэрэгтэй байдаг. Үүнийг дараах гурван аргаар хийж болно:
Санал болгож буй арга: here багцыг ашиглан файлын “харьцангуй (relative)” байршлыг олно.
Файлын “бүтэн” буюу “үнэмлэхүй (absolute)” байршлыг бичиж өгнө.
Гар аргаар (manual) файлыг сонгох
Файлын “харьцангуй (relative)” байршил
“Харьцангуй (relative)” байршил гэдэг нь файлын байршил R төслийн үндсэн хавтастай холбоотой байхыг хэлнэ. Ингэснээр өөр компьютер дээр ажиллах үед файлын байршлыг тогтооход маш хялбар болдог (тухайлбал R төслийг имэйлээр илгээх, эсвэл дундын драйв дээр ашиглах зэрэг үед). Дээр дурьдсанчлан “харьцангуй (relative)” байршлыг тогтоохдоо here багцыг ашиглана.
here()–ийг ашиглаж файлын харьцангуй байршлыг олох жишээг доор харуулав. Жишээнд R төслийн үндсэн хавтаст “data” гэсэн хавтас байх ба энэ хавтаст дахиад дэд хавтас болох “linelists” гэсэн хавтас байгаа ба үүн дотор бидний ажиллах .xlsx өргөтгөлтэй файл байгаа гэж үзсэн.
Файлын “үнэмлэхүй” байршил
Файлын “бүтэн” байршлыг import() зэрэг функцэд ашиглаж болох боловч энэ нь зөвхөн тухайн ажиллаж буй компьютерт л өвөрмөц байдаг тул хэрэглэхгүй байхыг зөвлөж байна.
Файлын үнэмлэхүй байршлын жишээг доор харуулав. Энд Лаурагийн компьютерт “analysis” дэд хавтас байгаа ба үүн доторх “data” дэд хавтас дотор “linelists” гэсэн дэд хавтас байна. Үүний дотор бидний ажиллаж буй .xlsx өргөтгөлтэй файл байрлаж буй.
linelist <- import("C:/Users/Laura/Documents/analysis/data/linelists/ebola_linelist.xlsx")Үнэмлэхүй байршлыг ашиглахад анхаарах зүйлс:
Өөр хүний компьютер дээр ажиллах үед файлын байршлын холбоос эвдэрдэг тул аль болох үнэмлэхүй файлын байршил хэрэглэхээс зайлсхий.
Урагшаа чиглэлтэй ташуу зураасыг (
/) ашигла (энэ нь ердийн Windows-ын үеийнхээс ӨӨР болохыг анхаар)Давхар ташуу зураасаар (e.g. “//…”) эхэлдэг файлын байршлууд R программд танигдахгүй байх өндөр магадлалтай ба алдаа заадаг. Ажлаа “нэртэй” эсвэл “J:”, “C:” гэх мэт үсгээр дугаарласан дискэнд хадгалахыг зөвлөж байна. Энэ талаар Directory interactions хэсгээс нэмж тодруулж болно.
Дундын драйв дээрх файлын байршил тэр файлыг хэрэглэж буй бүх хүний компьютерт адилхан байхаар бичигдсэн үед үнэмлэхүй байршлыг ашиглах нь зөв.
ЗӨВЛӨГӨӨ: \ тэмдэгтийг /-ээр түргэн солихын тулд Ctrl+f ( Windows-г) дарж гарах цэснээс “In selection”-г сонго. Үүний дараа тэмдэгт солих үйлдэл хийж нэг дор солих боломжтой.
Гар аргаар байршлыг сонгох
Дараах аргуудын аль нэгээр гар аргаар дата оруулж ирж болно:
RStudio–ын Орчин (Environment) табны “Import Dataset”-г дарж гарах цэснээс өгөгдлийн төрлийг сонгоно.
File / Import Dataset –г дарж өгөгдлийн төрлийг сонгоно
Гар аргаар сонголтыг кодлоё гэвэл base R–ын
file.choose()функцыг хоосон хаалттайгаар уншуулж pop-up цонхыг гаргаж ирэн файлаа өөрөө сонгож болдог. Жишээлбэл:
# Гар аргаар файл сонгох. Дараах командыг уншуулахад POP-UP цонх нээгдэнэ
# Сонгосон файлын байршил import() командын дотор бичигдэх болно.
my_data <- import(file.choose())ЗӨВЛӨГӨӨ: Pop-up цонх RStudio-гийн цонхны АРД нээгдсэн байж болохыг анхаар.
7.5 Дата импортлох
import()-г ашиглан датасет импортлох нь харьцангуй энгийн. Хаалтан дотор файлын байршлыг (файлын нэр өргөтгэлтэй нь хамт) хашилттай бичихэд болно. Хэрэв here()-г ашиглан файлын байршлыг тодорхойлох бол дээр дурьдсан жишээг харна уу. Хэдэн жишээнүүд:
Таны “ажлын хавтас”-т эсвэл R–ын үндсэн хавтаст байрлах csv файлыг оруулах:
linelist <- import("linelist_cleaned.csv")R төсөл дэх “data” хавтсын “linelists” дэд хавтасд буй Excel файлын эхний sheet–ийг оруулах (here()-г ашиглан хийсэн файлын зам ашиглаж буй үед):
Файлын үнэмлэхүй байршлыг дуудаж өгөгдлийг (.rds файл) оруулах:
linelist <- import("C:/Users/Laura/Documents/tuberculosis/data/linelists/linelist_cleaned.rds")Specific Excel sheets
By default, if you provide an Excel workbook (.xlsx) to import(), the workbook’s first sheet will be imported. If you want to import a specific sheet, include the sheet name to the which = argument. For example:
my_data <- import("my_excel_file.xlsx", which = "Sheetname")If using the here() method to provide a relative pathway to import(), you can still indicate a specific sheet by adding the which = argument after the closing parentheses of the here() function.
# Demonstration: importing a specific Excel sheet when using relative pathways with the 'here' package
linelist_raw <- import(here("data", "linelist.xlsx"), which = "Sheet1")` To export a data frame from R to a specific Excel sheet and have the rest of the Excel workbook remain unchanged, you will have to import, edit, and export with an alternative package catered to this purpose such as openxlsx. See more information in the page on Directory interactions or at this github page.
If your Excel workbook is .xlsb (binary format Excel workbook) you may not be able to import it using rio. Consider re-saving it as .xlsx, or using a package like readxlsb which is built for this purpose.
Missing values
You may want to designate which value(s) in your dataset should be considered as missing. As explained in the page on Missing data, the value in R for missing data is NA, but perhaps the dataset you want to import uses 99, “Missing”, or just empty character space "" instead.
Use the na = argument for import() and provide the value(s) within quotes (even if they are numbers). You can specify multiple values by including them within a vector, using c() as shown below.
Here, the value “99” in the imported dataset is considered missing and converted to NA in R.
Here, any of the values “Missing”, "" (empty cell), or " " (single space) in the imported dataset are converted to NA in R.
Skip rows
Sometimes, you may want to avoid importing a row of data. You can do this with the argument skip = if using import() from rio on a .xlsx or .csv file. Provide the number of rows you want to skip.
linelist_raw <- import("linelist_raw.xlsx", skip = 1) # does not import header rowUnfortunately skip = only accepts one integer value, not a range (e.g. “2:10” does not work). To skip import of specific rows that are not consecutive from the top, consider importing multiple times and using bind_rows() from dplyr. See the example below of skipping only row 2.
Manage a second header row
Sometimes, your data may have a second row, for example if it is a “data dictionary” row as shown below. This situation can be problematic because it can result in all columns being imported as class “character”.
Below is an example of this kind of dataset (with the first row being the data dictionary).
Remove the second header row
To drop the second header row, you will likely need to import the data twice.
- Import the data in order to store the correct column names
- Import the data again, skipping the first two rows (header and second rows)
- Bind the correct names onto the reduced dataframe
The exact argument used to bind the correct column names depends on the type of data file (.csv, .tsv, .xlsx, etc.). This is because rio is using a different function for the different file types (see table above).
For Excel files: (col_names =)
# import first time; store the column names
linelist_raw_names <- import("linelist_raw.xlsx") %>% names() # save true column names
# import second time; skip row 2, and assign column names to argument col_names =
linelist_raw <- import("linelist_raw.xlsx",
skip = 2,
col_names = linelist_raw_names
) For CSV files: (col.names =)
# import first time; sotre column names
linelist_raw_names <- import("linelist_raw.csv") %>% names() # save true column names
# note argument for csv files is 'col.names = '
linelist_raw <- import("linelist_raw.csv",
skip = 2,
col.names = linelist_raw_names
) Backup option - changing column names as a separate command
# assign/overwrite headers using the base 'colnames()' function
colnames(linelist_raw) <- linelist_raw_namesMake a data dictionary
Bonus! If you do have a second row that is a data dictionary, you can easily create a proper data dictionary from it. This tip is adapted from this post.
dict <- linelist_2headers %>% # begin: linelist with dictionary as first row
head(1) %>% # keep only column names and first dictionary row
pivot_longer(cols = everything(), # pivot all columns to long format
names_to = "Column", # assign new column names
values_to = "Description")Combine the two header rows
In some cases when your raw dataset has two header rows (or more specifically, the 2nd row of data is a secondary header), you may want to “combine” them or add the values in the second header row into the first header row.
The command below will define the data frame’s column names as the combination (pasting together) of the first (true) headers with the value immediately underneath (in the first row).
Google sheets
You can import data from an online Google spreadsheet with the googlesheet4 package and by authenticating your access to the spreadsheet.
pacman::p_load("googlesheets4")Below, a demo Google sheet is imported and saved. This command may prompt confirmation of authentification of your Google account. Follow prompts and pop-ups in your internet browser to grant Tidyverse API packages permissions to edit, create, and delete your spreadsheets in Google Drive.
The sheet below is “viewable for anyone with the link” and you can try to import it.
Gsheets_demo <- read_sheet("https://docs.google.com/spreadsheets/d/1scgtzkVLLHAe5a6_eFQEwkZcc14yFUx1KgOMZ4AKUfY/edit#gid=0")The sheet can also be imported using only the sheet ID, a shorter part of the URL:
Gsheets_demo <- read_sheet("1scgtzkVLLHAe5a6_eFQEwkZcc14yFUx1KgOMZ4AKUfY")Another package, googledrive offers useful functions for writing, editing, and deleting Google sheets. For example, using the gs4_create() and sheet_write() functions found in this package.
Here are some other helpful online tutorials:
basic Google sheets importing tutorial
more detailed tutorial
interaction between the googlesheets4 and tidyverse
7.6 Multiple files - import, export, split, combine
See the page on Iteration, loops, and lists for examples of how to import and combine multiple files, or multiple Excel workbook files. That page also has examples on how to split a data frame into parts and export each one separately, or as named sheets in an Excel workbook.
7.7 Import from Github
Importing data directly from Github into R can be very easy or can require a few steps - depending on the file type. Below are some approaches:
CSV files
It can be easy to import a .csv file directly from Github into R with an R command.
- Go to the Github repo, locate the file of interest, and click on it
- Click on the “Raw” button (you will then see the “raw” csv data, as shown below)
- Copy the URL (web address)
- Place the URL in quotes within the
import()R command
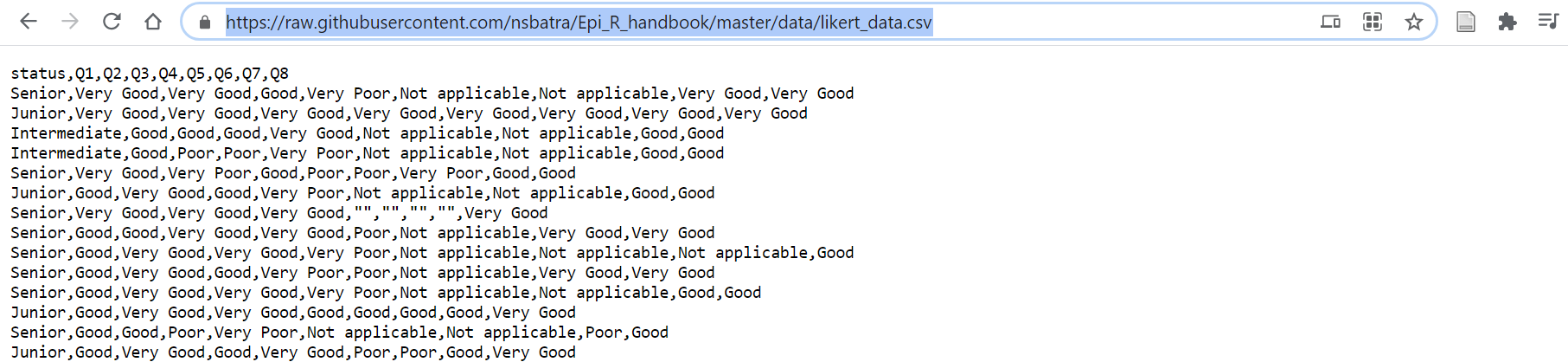
XLSX files
You may not be able to view the “Raw” data for some files (e.g. .xlsx, .rds, .nwk, .shp)
- Go to the Github repo, locate the file of interest, and click on it
- Click the “Download” button, as shown below
- Save the file on your computer, and import it into R
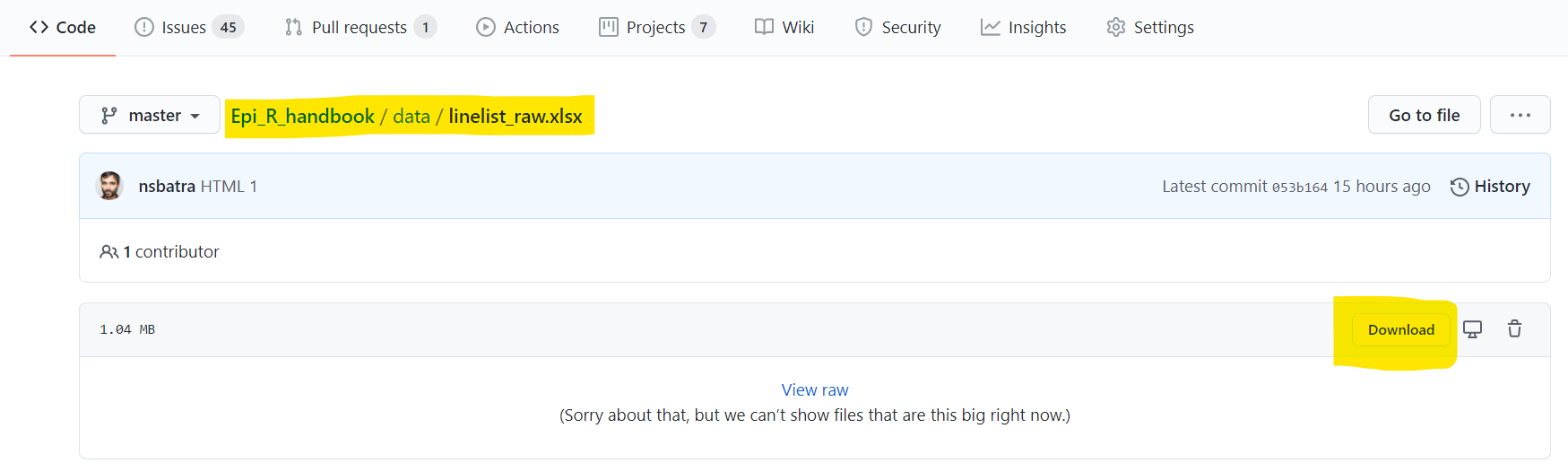
Shapefiles
Shapefiles have many sub-component files, each with a different file extention. One file will have the “.shp” extension, but others may have “.dbf”, “.prj”, etc. To download a shapefile from Github, you will need to download each of the sub-component files individually, and save them in the same folder on your computer. In Github, click on each file individually and download them by clicking on the “Download” button.
Once saved to your computer you can import the shapefile as shown in the GIS basics page using st_read() from the sf package. You only need to provide the filepath and name of the “.shp” file - as long as the other related files are within the same folder on your computer.
Below, you can see how the shapefile “sle_adm3” consists of many files - each of which must be downloaded from Github.
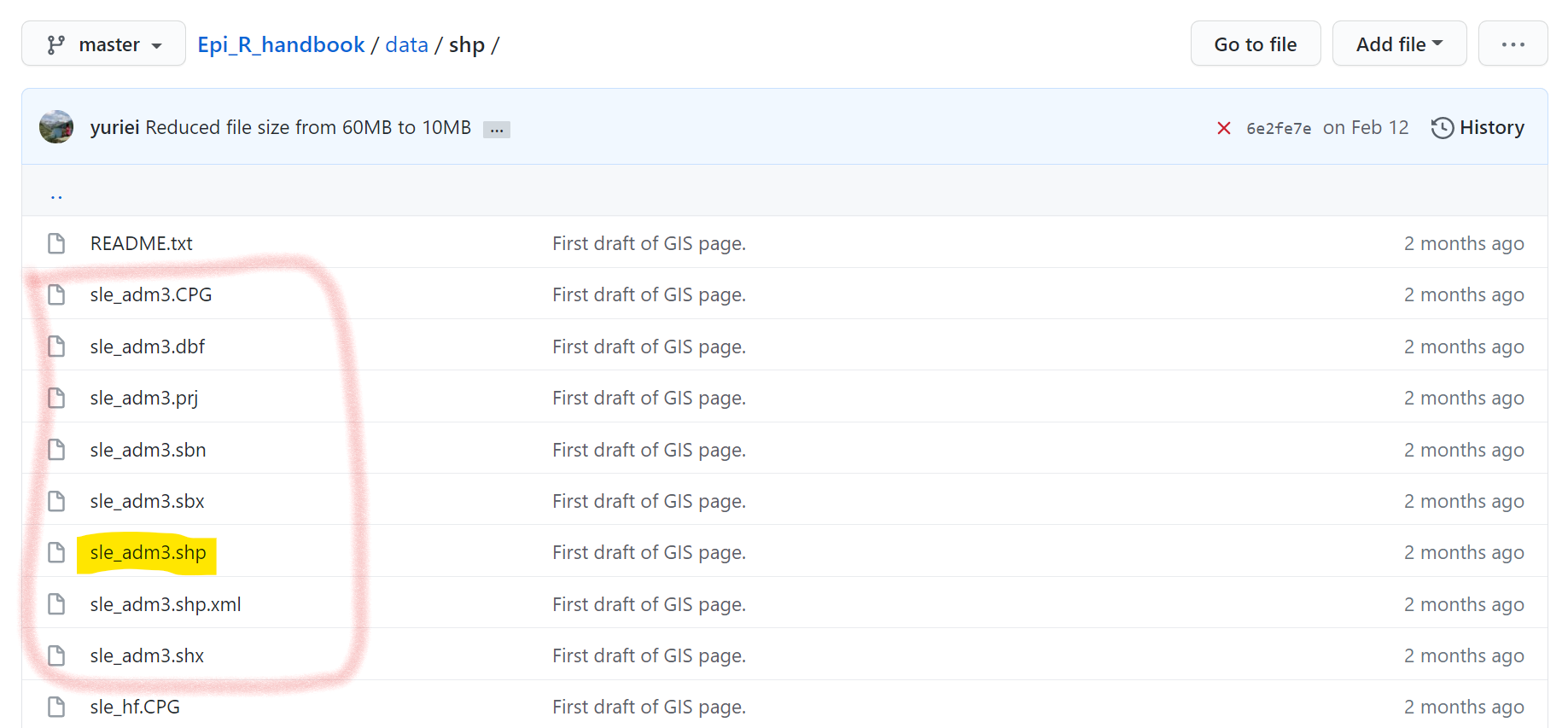
7.8 Manual data entry
Entry by rows
Use the tribble function from the tibble package from the tidyverse (online tibble reference).
Note how column headers start with a tilde (~). Also note that each column must contain only one class of data (character, numeric, etc.). You can use tabs, spacing, and new rows to make the data entry more intuitive and readable. Spaces do not matter between values, but each row is represented by a new line of code. For example:
# create the dataset manually by row
manual_entry_rows <- tibble::tribble(
~colA, ~colB,
"a", 1,
"b", 2,
"c", 3
)And now we display the new dataset:
Entry by columns
Since a data frame consists of vectors (vertical columns), the base approach to manual dataframe creation in R expects you to define each column and then bind them together. This can be counter-intuitive in epidemiology, as we usually think about our data in rows (as above).
# define each vector (vertical column) separately, each with its own name
PatientID <- c(235, 452, 778, 111)
Treatment <- c("Yes", "No", "Yes", "Yes")
Death <- c(1, 0, 1, 0)CAUTION: All vectors must be the same length (same number of values).
The vectors can then be bound together using the function data.frame():
# combine the columns into a data frame, by referencing the vector names
manual_entry_cols <- data.frame(PatientID, Treatment, Death)And now we display the new dataset:
Pasting from clipboard
If you copy data from elsewhere and have it on your clipboard, you can try one of the two ways below:
From the clipr package, you can use read_clip_tbl() to import as a data frame, or just just read_clip() to import as a character vector. In both cases, leave the parentheses empty.
linelist <- clipr::read_clip_tbl() # imports current clipboard as data frame
linelist <- clipr::read_clip() # imports as character vectorYou can also easily export to your system’s clipboard with clipr. See the section below on Export.
Alternatively, you can use the the read.table() function from base R with file = "clipboard") to import as a data frame:
df_from_clipboard <- read.table(
file = "clipboard", # specify this as "clipboard"
sep = "t", # separator could be tab, or commas, etc.
header=TRUE) # if there is a header row7.9 Import most recent file
Often you may receive daily updates to your datasets. In this case you will want to write code that imports the most recent file. Below we present two ways to approach this:
- Selecting the file based on the date in the file name
- Selecting the file based on file metadata (last modification)
Dates in file name
This approach depends on three premises:
- You trust the dates in the file names
- The dates are numeric and appear in generally the same format (e.g. year then month then day)
- There are no other numbers in the file name
We will explain each step, and then show you them combined at the end.
First, use dir() from base R to extract just the file names for each file in the folder of interest. See the page on Directory interactions for more details about dir(). In this example, the folder of interest is the folder “linelists” within the folder “example” within “data” within the R project.
linelist_filenames <- dir(here("data", "example", "linelists")) # get file names from folder
linelist_filenames # print## [1] "20201007linelist.csv" "case_linelist_2020-10-02.csv" "case_linelist_2020-10-03.csv"
## [4] "case_linelist_2020-10-04.csv" "case_linelist_2020-10-05.csv" "case_linelist_2020-10-08.xlsx"
## [7] "case_linelist20201006.csv"Once you have this vector of names, you can extract the dates from them by applying str_extract() from stringr using this regular expression. It extracts any numbers in the file name (including any other characters in the middle such as dashes or slashes). You can read more about stringr in the [Strings and characters] page.
linelist_dates_raw <- stringr::str_extract(linelist_filenames, "[0-9].*[0-9]") # extract numbers and any characters in between
linelist_dates_raw # print## [1] "20201007" "2020-10-02" "2020-10-03" "2020-10-04" "2020-10-05" "2020-10-08" "20201006"Assuming the dates are written in generally the same date format (e.g. Year then Month then Day) and the years are 4-digits, you can use lubridate’s flexible conversion functions (ymd(), dmy(), or mdy()) to convert them to dates. For these functions, the dashes, spaces, or slashes do not matter, only the order of the numbers. Read more in the Working with dates page.
linelist_dates_clean <- lubridate::ymd(linelist_dates_raw)
linelist_dates_clean## [1] "2020-10-07" "2020-10-02" "2020-10-03" "2020-10-04" "2020-10-05" "2020-10-08" "2020-10-06"The base R function which.max() can then be used to return the index position (e.g. 1st, 2nd, 3rd, …) of the maximum date value. The latest file is correctly identified as the 6th file - “case_linelist_2020-10-08.xlsx”.
index_latest_file <- which.max(linelist_dates_clean)
index_latest_file## [1] 6If we condense all these commands, the complete code could look like below. Note that the . in the last line is a placeholder for the piped object at that point in the pipe sequence. At that point the value is simply the number 6. This is placed in double brackets to extract the 6th element of the vector of file names produced by dir().
# load packages
pacman::p_load(
tidyverse, # data management
stringr, # work with strings/characters
lubridate, # work with dates
rio, # import / export
here, # relative file paths
fs) # directory interactions
# extract the file name of latest file
latest_file <- dir(here("data", "example", "linelists")) %>% # file names from "linelists" sub-folder
str_extract("[0-9].*[0-9]") %>% # pull out dates (numbers)
ymd() %>% # convert numbers to dates (assuming year-month-day format)
which.max() %>% # get index of max date (latest file)
dir(here("data", "example", "linelists"))[[.]] # return the filename of latest linelist
latest_file # print name of latest file## [1] "case_linelist_2020-10-08.xlsx"You can now use this name to finish the relative file path, with here():
here("data", "example", "linelists", latest_file) And you can now import the latest file:
Use the file info
If your files do not have dates in their names (or you do not trust those dates), you can try to extract the last modification date from the file metadata. Use functions from the package fs to examine the metadata information for each file, which includes the last modification time and the file path.
Below, we provide the folder of interest to fs’s dir_info(). In this case, the folder of interest is in the R project in the folder “data”, the sub-folder “example”, and its sub-folder “linelists”. The result is a data frame with one line per file and columns for modification_time, path, etc. You can see a visual example of this in the page on Directory interactions.
We can sort this data frame of files by the column modification_time, and then keep only the top/latest row (file) with base R’s head(). Then we can extract the file path of this latest file only with the dplyr function pull() on the column path. Finally we can pass this file path to import(). The imported file is saved as latest_file.
7.10 APIs
An “Automated Programming Interface” (API) can be used to directly request data from a website. APIs are a set of rules that allow one software application to interact with another. The client (you) sends a “request” and receives a “response” containing content. The R packages httr and jsonlite can facilitate this process.
Each API-enabled website will have its own documentation and specifics to become familiar with. Some sites are publicly available and can be accessed by anyone. Others, such as platforms with user IDs and credentials, require authentication to access their data.
Needless to say, it is necessary to have an internet connection to import data via API. We will briefly give examples of use of APIs to import data, and link you to further resources.
Note: recall that data may be posted* on a website without an API, which may be easier to retrieve. For example a posted CSV file may be accessible simply by providing the site URL to import() as described in the section on importing from Github.*
HTTP request
The API exchange is most commonly done through an HTTP request. HTTP is Hypertext Transfer Protocol, and is the underlying format of a request/response between a client and a server. The exact input and output may vary depending on the type of API but the process is the same - a “Request” (often HTTP Request) from the user, often containing a query, followed by a “Response”, containing status information about the request and possibly the requested content.
Here are a few components of an HTTP request:
- The URL of the API endpoint
- The “Method” (or “Verb”)
- Headers
- Body
The HTTP request “method” is the action your want to perform. The two most common HTTP methods are GET and POST but others could include PUT, DELETE, PATCH, etc. When importing data into R it is most likely that you will use GET.
After your request, your computer will receive a “response” in a format similar to what you sent, including URL, HTTP status (Status 200 is what you want!), file type, size, and the desired content. You will then need to parse this response and turn it into a workable data frame within your R environment.
Packages
The httr package works well for handling HTTP requests in R. It requires little prior knowledge of Web APIs and can be used by people less familiar with software development terminology. In addition, if the HTTP response is .json, you can use jsonlite to parse the response.
# load packages
pacman::p_load(httr, jsonlite, tidyverse)Publicly-available data
Below is an example of an HTTP request, borrowed from a tutorial from the Trafford Data Lab. This site has several other resources to learn and API exercises.
Scenario: We want to import a list of fast food outlets in the city of Trafford, UK. The data can be accessed from the API of the Food Standards Agency, which provides food hygiene rating data for the United Kingdom.
Here are the parameters for our request:
- HTTP verb: GET
- API endpoint URL: http://api.ratings.food.gov.uk/Establishments
- Selected parameters: name, address, longitude, latitude, businessTypeId, ratingKey, localAuthorityId
- Headers: “x-api-version”, 2
- Data format(s): JSON, XML
- Documentation: http://api.ratings.food.gov.uk/help
The R code would be as follows:
# prepare the request
path <- "http://api.ratings.food.gov.uk/Establishments"
request <- GET(url = path,
query = list(
localAuthorityId = 188,
BusinessTypeId = 7844,
pageNumber = 1,
pageSize = 5000),
add_headers("x-api-version" = "2"))
# check for any server error ("200" is good!)
request$status_code
# submit the request, parse the response, and convert to a data frame
response <- content(request, as = "text", encoding = "UTF-8") %>%
fromJSON(flatten = TRUE) %>%
pluck("establishments") %>%
as_tibble()You can now clean and use the response data frame, which contains one row per fast food facility.
Authentication required
Some APIs require authentication - for you to prove who you are, so you can access restricted data. To import these data, you may need to first use a POST method to provide a username, password, or code. This will return an access token, that can be used for subsequent GET method requests to retrieve the desired data.
Below is an example of querying data from Go.Data, which is an outbreak investigation tool. Go.Data uses an API for all interactions between the web front-end and smartphone applications used for data collection. Go.Data is used throughout the world. Because outbreak data are sensitive and you should only be able to access data for your outbreak, authentication is required.
Below is some sample R code using httr and jsonlite for connecting to the Go.Data API to import data on contact follow-up from your outbreak.
# set credentials for authorization
url <- "https://godatasampleURL.int/" # valid Go.Data instance url
username <- "username" # valid Go.Data username
password <- "password" # valid Go,Data password
outbreak_id <- "xxxxxx-xxxx-xxxx-xxxx-xxxxxxx" # valid Go.Data outbreak ID
# get access token
url_request <- paste0(url,"api/oauth/token?access_token=123") # define base URL request
# prepare request
response <- POST(
url = url_request,
body = list(
username = username, # use saved username/password from above to authorize
password = password),
encode = "json")
# execute request and parse response
content <-
content(response, as = "text") %>%
fromJSON(flatten = TRUE) %>% # flatten nested JSON
glimpse()
# Save access token from response
access_token <- content$access_token # save access token to allow subsequent API calls below
# import outbreak contacts
# Use the access token
response_contacts <- GET(
paste0(url,"api/outbreaks/",outbreak_id,"/contacts"), # GET request
add_headers(
Authorization = paste("Bearer", access_token, sep = " ")))
json_contacts <- content(response_contacts, as = "text") # convert to text JSON
contacts <- as_tibble(fromJSON(json_contacts, flatten = TRUE)) # flatten JSON to tibbleCAUTION: If you are importing large amounts of data from an API requiring authentication, it may time-out. To avoid this, retrieve access_token again before each API GET request and try using filters or limits in the query.
TIP: The fromJSON() function in the jsonlite package does not fully un-nest the first time it’s executed, so you will likely still have list items in your resulting tibble. You will need to further un-nest for certain variables; depending on how nested your .json is. To view more info on this, view the documentation for the jsonlite package, such as the flatten() function.
For more details, View documentation on LoopBack Explorer, the Contact Tracing page or API tips on Go.Data Github repository
You can read more about the httr package here
This section was also informed by this tutorial and this tutorial.
7.11 Export
With rio package
With rio, you can use the export() function in a very similar way to import(). First give the name of the R object you want to save (e.g. linelist) and then in quotes put the file path where you want to save the file, including the desired file name and file extension. For example:
This saves the data frame linelist as an Excel workbook to the working directory/R project root folder:
export(linelist, "my_linelist.xlsx") # will save to working directoryYou could save the same data frame as a csv file by changing the extension. For example, we also save it to a file path constructed with here():
To clipboard
To export a data frame to your computer’s “clipboard” (to then paste into another software like Excel, Google Spreadsheets, etc.) you can use write_clip() from the clipr package.
# export the linelist data frame to your system's clipboard
clipr::write_clip(linelist)7.12 RDS files
Along with .csv, .xlsx, etc, you can also export/save R data frames as .rds files. This is a file format specific to R, and is very useful if you know you will work with the exported data again in R.
The classes of columns are stored, so you don’t have do to cleaning again when it is imported (with an Excel or even a CSV file this can be a headache!). It is also a smaller file, which is useful for export and import if your dataset is large.
For example, if you work in an Epidemiology team and need to send files to a GIS team for mapping, and they use R as well, just send them the .rds file! Then all the column classes are retained and they have less work to do.
7.13 Rdata files and lists
.Rdata files can store multiple R objects - for example multiple data frames, model results, lists, etc. This can be very useful to consolidate or share a lot of your data for a given project.
In the below example, multiple R objects are stored within the exported file “my_objects.Rdata”:
rio::export(my_list, my_dataframe, my_vector, "my_objects.Rdata")Note: if you are trying to import a list, use import_list() from rio to import it with the complete original structure and contents.
rio::import_list("my_list.Rdata")7.14 Saving plots
Instructions on how to save plots, such as those created by ggplot(), are discussed in depth in the ggplot basics page.
In brief, run ggsave("my_plot_filepath_and_name.png") after printing your plot. You can either provide a saved plot object to the plot = argument, or only specify the destination file path (with file extension) to save the most recently-displayed plot. You can also control the width =, height =, units =, and dpi =.
How to save a network graph, such as a transmission tree, is addressed in the page on Transmission chains.
7.15 Resources
The R Data Import/Export Manual
R 4 Data Science chapter on data import
ggsave() documentation
Below is a table, taken from the rio online vignette. For each type of data it shows: the expected file extension, the package rio uses to import or export the data, and whether this functionality is included in the default installed version of rio.
| Format | Typical Extension | Import Package | Export Package | Installed by Default |
|---|---|---|---|---|
| Comma-separated data | .csv | data.table fread()
|
data.table | Yes |
| Pipe-separated data | .psv | data.table fread()
|
data.table | Yes |
| Tab-separated data | .tsv | data.table fread()
|
data.table | Yes |
| SAS | .sas7bdat | haven | haven | Yes |
| SPSS | .sav | haven | haven | Yes |
| Stata | .dta | haven | haven | Yes |
| SAS | XPORT | .xpt | haven | haven |
| SPSS Portable | .por | haven | Yes | |
| Excel | .xls | readxl | Yes | |
| Excel | .xlsx | readxl | openxlsx | Yes |
| R syntax | .R | base | base | Yes |
| Saved R objects | .RData, .rda | base | base | Yes |
| Serialized R objects | .rds | base | base | Yes |
| Epiinfo | .rec | foreign | Yes | |
| Minitab | .mtp | foreign | Yes | |
| Systat | .syd | foreign | Yes | |
| “XBASE” | database files | .dbf | foreign | foreign |
| Weka Attribute-Relation File Format | .arff | foreign | foreign | Yes |
| Data Interchange Format | .dif | utils | Yes | |
| Fortran data | no recognized extension | utils | Yes | |
| Fixed-width format data | .fwf | utils | utils | Yes |
| gzip comma-separated data | .csv.gz | utils | utils | Yes |
| CSVY (CSV + YAML metadata header) | .csvy | csvy | csvy | No |
| EViews | .wf1 | hexView | No | |
| Feather R/Python interchange format | .feather | feather | feather | No |
| Fast Storage | .fst | fst | fst | No |
| JSON | .json | jsonlite | jsonlite | No |
| Matlab | .mat | rmatio | rmatio | No |
| OpenDocument Spreadsheet | .ods | readODS | readODS | No |
| HTML Tables | .html | xml2 | xml2 | No |
| Shallow XML documents | .xml | xml2 | xml2 | No |
| YAML | .yml | yaml | yaml | No |
| Clipboard default is tsv | clipr | clipr | No |